
Synthesizing Realistic Human Motion with Limited Data
In the world of animating virtual avatars, realism is the holy grail. But capturing the nuanced, expressive motions of real humans typically demands massive datasets, expensive motion capture equipment, and time-intensive post-processing.
We propose a generative framework that can synthesize expressive, controllable human motion, even when trained on just a few minutes of motion data. Let’s dive into what makes this method stand out and why it matters for animation, virtual humans, and beyond.
Why Is Human Motion Difficult to Synthesize?
Human movement isn’t just about limbs swinging from A to B. It has different dimensions regarding emotion, context, and subtle details. Traditionally, deep learning methods rely on large amounts of motion capture data to reproduce these nuances. But depending on the use case, this can be a limiting factor.
We propose a multi-resolution approach that builds motion from coarse to fine scales and introduces conditional control at each stage.
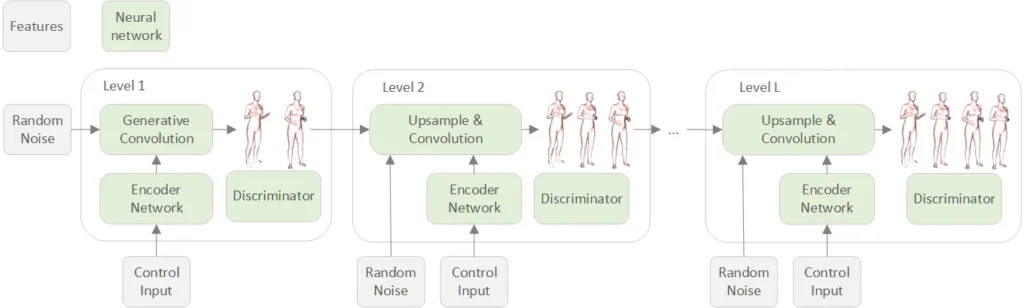
The Innovation: Multi-Resolution Motion Synthesis
In our work, we employ a multi-scale generative adversarial network (GAN) architecture. Instead of trying to generate complex motion at once, the model progressively builds it up:
- Temporally coarse motion is generated first, capturing the overall movement or action (e.g., walking, gesturing).
- Finer details, such as subtle head tilts or expressive upper body movements are added in later steps.
- Control signals (like one-hot encodings of action labels or speech audio) guide the generation process at each resolution step, providing users with detailed control over style and content.
How do we achieve this? By using Feature-wise Linear Modulation (FiLM) to integrate these signals seamlessly at each temporal resolution level.
Why does it work with so little data?
The real kicker here is that the model achieves high-quality, diverse outputs using just 3–4 minutes of motion data per sequence. That’s thanks to a patch-based GAN training, which encourages realism in short motion snippets.
Fine-Grained Control and Style Modulation
Our framework additionally includes other features:
- SMPL-based representation: we directly generate body pose parameters, which allows skipping expensive mesh fitting during test time.
- Style mixing: the model learns to combine motions (e.g., walking + angry expression) by mixing control signals at different time resolutions.
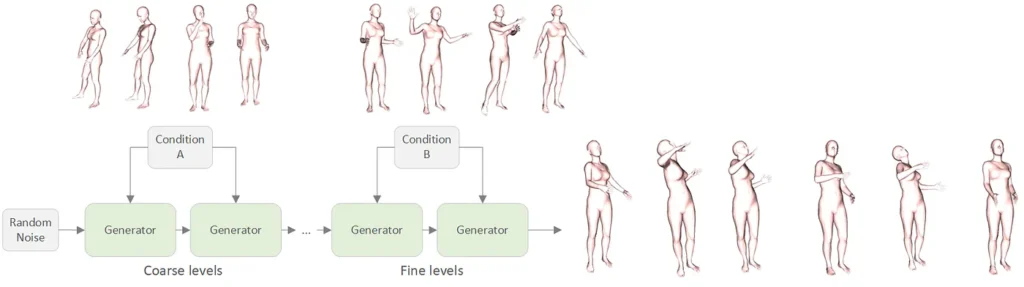
In contrast to previous models like GANimator (which required training separate models for each motion type), this unified model can mix and match styles in a single architecture.
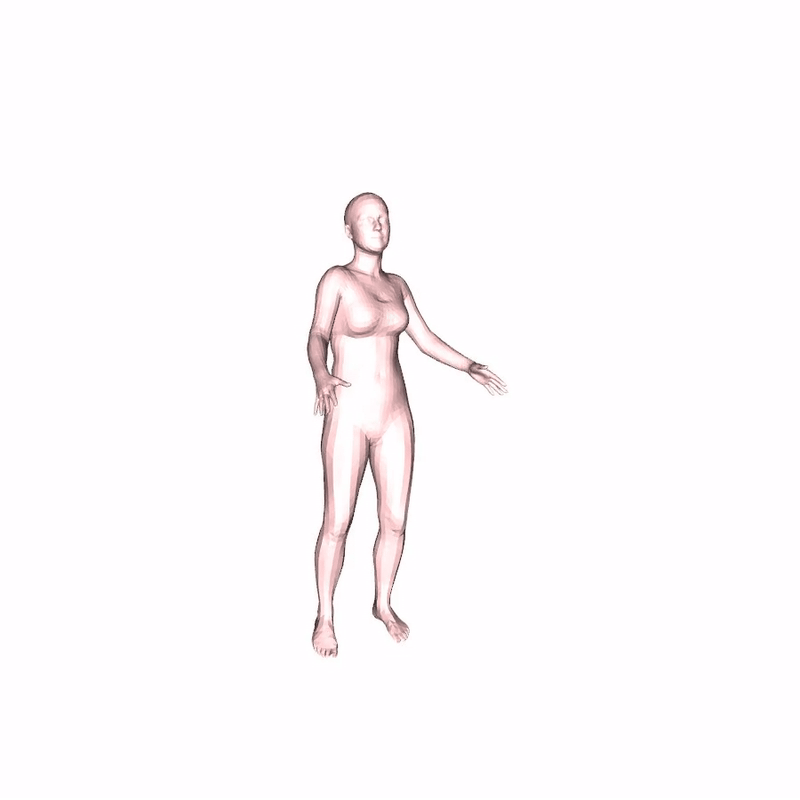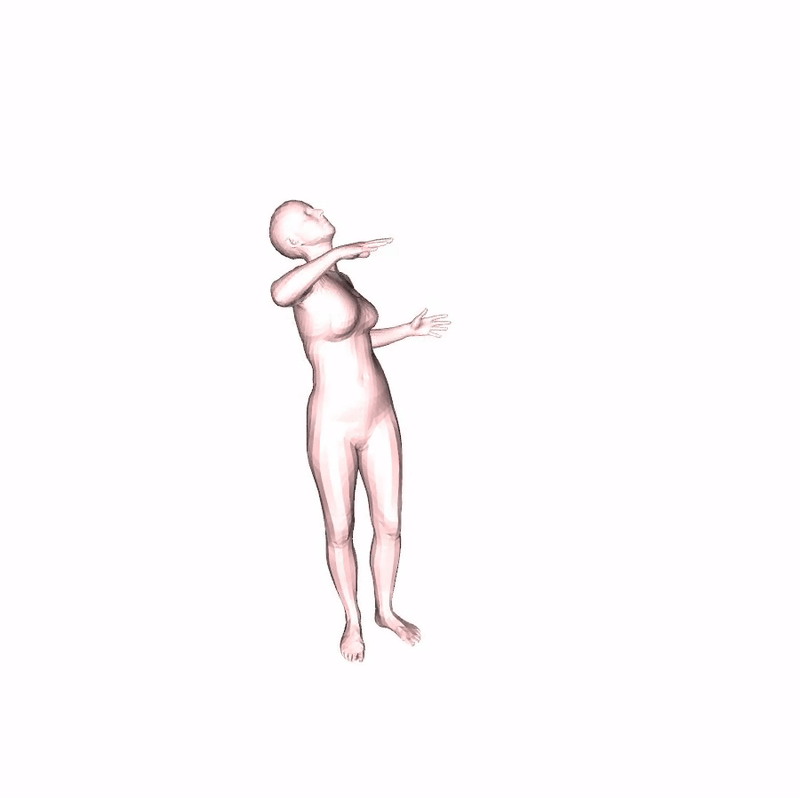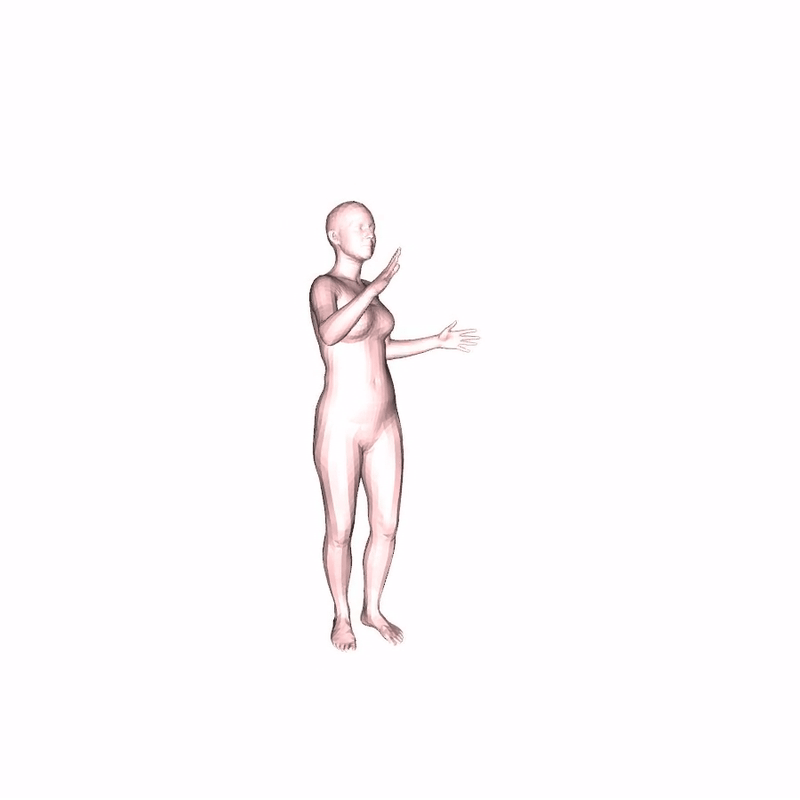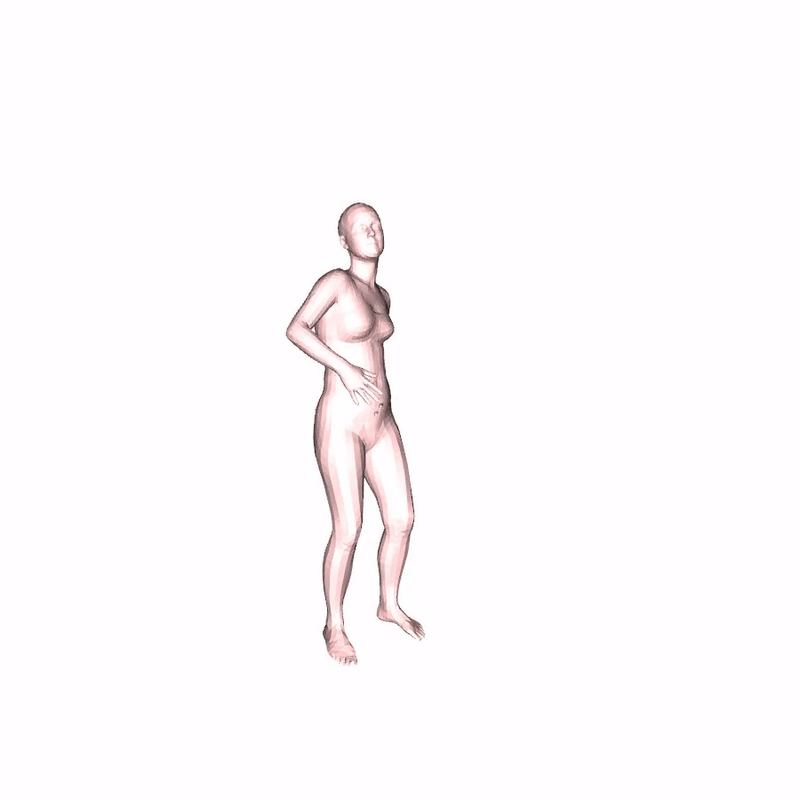
Beyond Action Labels: Speech-to-Gesture from Limited Data
We also propose an application for co-speech gesture synthesis: creating upper-body gestures synced to speech input.
We train our model with 23 minutes of data and only 16 paired speech-motion recordings, the model generates gestures aligned with new audio. We also incorporate unpaired audio data using some training tricks to improve generalization.
This opens up possibilities for natural-looking virtual presenters or avatars, without needing expensive resources.
Summary
Motion synthesis remains a dynamic and actively evolving field. In this regard, we propose a robust, data-efficient, and flexible framework that broadens access to high-quality human animation. Its strength lies in generating controllable motion even when training data is scarce, making it especially valuable for applications in games, virtual reality, and education.
Why is it exciting? It has potential for interactive systems where an avatar can respond to speech with expressive, human-like movement without retraining the model for each new task or context.
📌 Read the full paper here.