
Evaluating Multimodal Models: Are Our Benchmarks Enough?
In recent years, vision-language models (VLMs) have exploded in popularity. From CLIP, LLaVa and more recently PaLI-Gemma, the field has moved towards models capable of processing both images and text. These systems promise powerful capabilities across domains — from education and accessibility to robotics and document processing. But as this line of research advances, there is one question that we need to keep in mind:
How do we evaluate these models?
Why Evaluation Matters
Different VLMs have different strengths. Some are trained primarily on natural images and captions, while others are fine-tuned on documents, charts, or even diagrams. Architectural choices — like whether a model uses a transformer-based image encoder or relies on region features — can have a huge impact on performance for specific tasks.
This means there is no one-size-fits-all solution. Depending on the application — say, answering questions about a scientific diagram vs. interpreting a business chart — the best model can vary significantly. That’s why rigorous, thoughtful evaluation is essential.
The Current State of Evaluation
So, how are VLMs evaluated today? The short answer: mostly through benchmark datasets. These datasets pose questions or tasks for the model to solve, typically structured as question-answer pairs. Some of the most widely used include:
- VQA (Visual Question Answering)
Link — 760K questions, generally short, one-word answers. - DocVQA
Link — Questions about text in documents (50K examples). - ChartQA
Link — Understanding and reasoning over data visualizations. - AI2D
Link — 15K multiple-choice questions on diagrams. - TextVQA
Link — 45K questions focused on reading text in images. - MMMU
Website — A multi-domain, expert-level dataset with 11.5K questions. - MathVista
Link — Visual math problems with diagrammatic reasoning. - MM-Bench
Link — 3K vision-language questions with multiple-choice answers.
These benchmarks offer a solid foundation for comparison — but they’re often limited to multiple choice questions, which deviates from the real use-cases.
The Limitations We Need to Address
While benchmark datasets are useful, current evaluation methods lean heavily on multiple-choice question answering and image captioning. This leads to several core challenges:
1. Artificial Evaluation Settings
Multiple-choice questions offer clear metrics (accuracy), but they’re not representative of real-world usage. When you ask a model, “What does this chart say about sales in Q4?” you don’t provide four possible answers — you expect an open-ended, context-aware response.
Moreover, multiple-choice setups can mask weaknesses. Models may exploit statistical patterns or biases in the dataset without truly understanding the content — problems that have long plagued datasets like SNLI and MMLU.
2. Weakness in Multimodal Reasoning
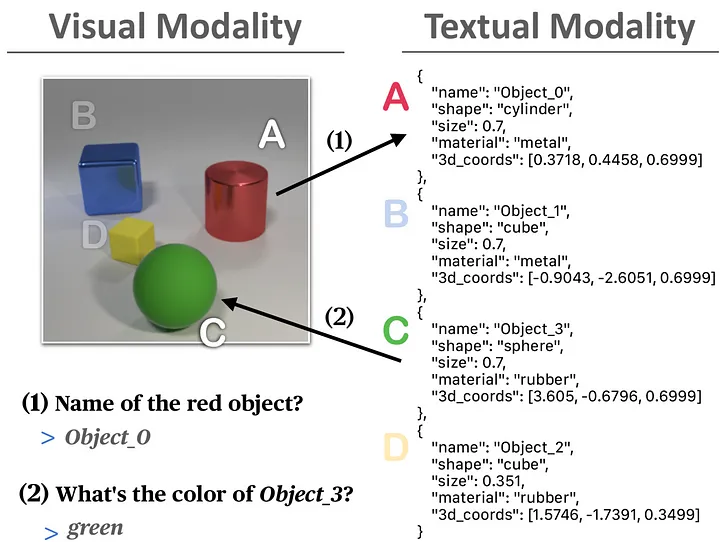
Many VLMs can recognize entities in individual modalities — text in a document, or objects in an image. But connecting information across modalities remains a major challenge. This is particularly apparent in tasks like visual multimodal entity linking. In our European Project LUMINOUS, we are actively working on manners to evaluate and improve this aspect. For example, we have created a dataset (MATE) where we probe VLMs ability to perform simple linking tasks which require understanding both visual and textual modalities.
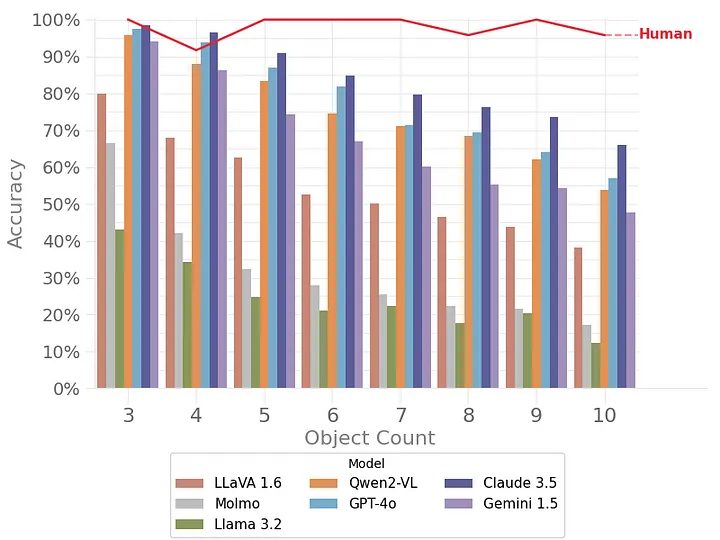
In the chart below, you can see that even SoTA VLMs struggle to link between modalities as the number of objects increases, despite human performance being level across the number of objects. Strikingly, this suggests that VLMs are currently not able to correctly combine information they have available in separate modalities.
3. Ambiguity in Natural Input
Real users often ask vague or underspecified questions. Yet our benchmarks rarely test models in these scenarios. Can the model handle ambiguous queries? Can it ask clarifying questions or make reasonable assumptions based on context? These nuances are largely missing from current evaluations.
Where Do We Go From Here?
To truly assess multimodal models, we need to move beyond rigid benchmarks and into more realistic evaluation scenarios. Some promising directions include:
- Open-ended evaluation tasks, where models must generate full responses or summaries based on visual and textual inputs.
- Interactive evaluation, where models respond to follow-up or clarifying questions.
- Task-based evaluations, where models complete a goal (e.g., extract structured data from a receipt) instead of simply answering a question.
- Bias and robustness checks, ensuring models perform consistently across diverse content and aren’t exploiting spurious patterns.
Final Thoughts
Benchmarking VLMs is a necessary first step — but it’s only the beginning. As these models move into more domains and user-facing applications, evaluation must evolve to keep pace with reality. We need tools that test not just accuracy, but adaptability, reasoning, and robustness across modalities. Most importantly, we need to be sure that we understand what we are evaluating.